🔍 Web Scraping: Panduan Lengkap dan Pentingnya dalam Era Digital
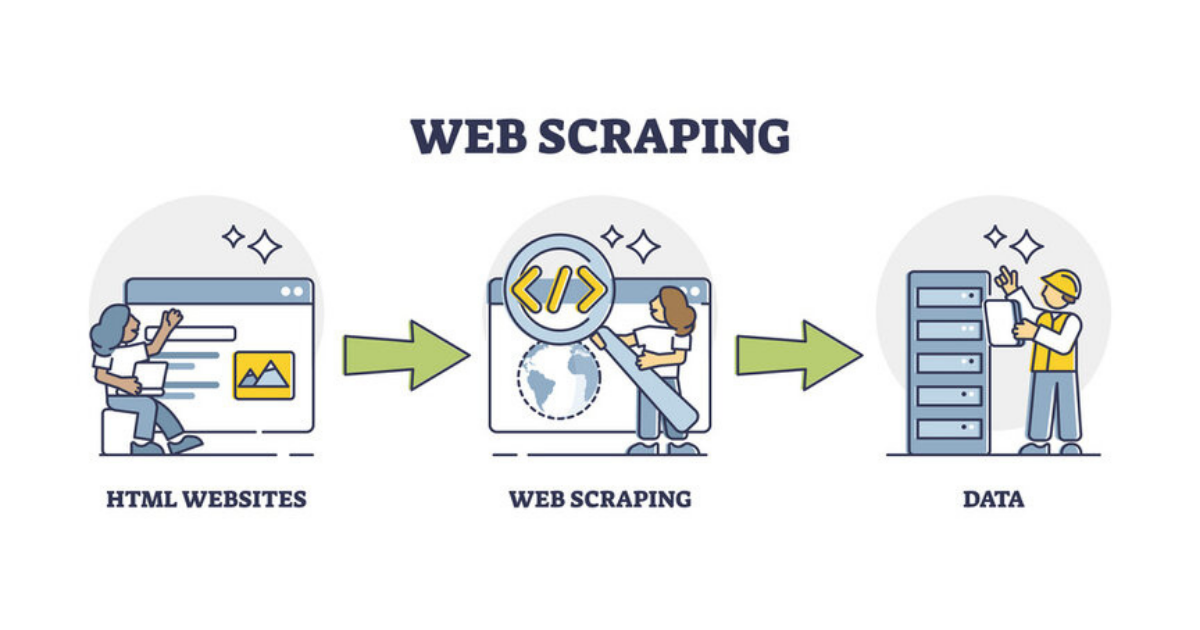
Apa itu Web Scraping?
Web scraping adalah teknik untuk mengekstrak data dari situs web. Proses ini menggunakan perangkat lunak khusus untuk mengumpulkan informasi dari halaman web dan mengubahnya menjadi format yang lebih terstruktur untuk dianalisis atau digunakan kembali. Web scraping memungkinkan pengguna untuk:
- Mengambil data dalam jumlah besar secara otomatis
- Mengubah data tidak terstruktur menjadi data terstruktur
- Memperoleh data yang tidak tersedia melalui API resmi
- Mengumpulkan informasi dari berbagai sumber secara efisien
Bagaimana Web Scraping Bekerja?
Secara umum, proses web scraping melibatkan beberapa langkah:
- Pengiriman Permintaan HTTP: Scraper mengirim permintaan ke server web
- Pengambilan Konten: Scraper mengunduh konten halaman web (biasanya HTML)
- Parsing Data: Scraper mengekstrak informasi yang diinginkan dari konten
- Penyimpanan Data: Data yang diambil disimpan dalam format terstruktur (CSV, JSON, database, dll.)
Tools dan Teknik Web Scraping
Python: Bahasa Populer untuk Web Scraping
Python adalah salah satu bahasa pemrograman yang paling populer untuk web scraping karena kemudahan penggunaannya dan dukungan pustaka yang lengkap.
Libraries Python untuk Web Scraping:
BeautifulSoup
BeautifulSoup adalah pustaka parsing HTML dan XML yang membuat navigasi struktur HTML menjadi mudah.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from bs4 import BeautifulSoup
import requests
# Mengambil konten halaman web
url = 'https://example.com'
response = requests.get(url)
html = response.content
# Parsing HTML
soup = BeautifulSoup(html, 'html.parser')
# Mengambil semua judul
titles = soup.find_all('h2')
for title in titles:
print(title.text)
Scrapy
Scrapy adalah framework web scraping yang lebih komprehensif untuk aplikasi yang lebih besar.
1
2
3
4
5
6
7
8
9
10
11
12
13
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example'
start_urls = ['https://example.com']
def parse(self, response):
for article in response.css('article'):
yield {
'title': article.css('h2::text').get(),
'content': article.css('p::text').get(),
'link': article.css('a::attr(href)').get()
}
Selenium
Selenium digunakan untuk scraping halaman web dinamis yang memuat konten melalui JavaScript.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# Menyiapkan driver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
# Membuka halaman web
driver.get('https://example.com')
# Menunggu konten JavaScript termuat
driver.implicitly_wait(10)
# Mengambil data
elements = driver.find_elements_by_css_selector('div.product')
for element in elements:
name = element.find_element_by_css_selector('.name').text
price = element.find_element_by_css_selector('.price').text
print(f'{name}: {price}')
# Menutup browser
driver.quit()
Mengapa Web Scraping Penting?
1. Pengambilan Keputusan Berbasis Data
Data adalah aset berharga dalam era digital ini. Web scraping memungkinkan organisasi dan individu untuk mengumpulkan data dan mendapatkan wawasan yang dapat membantu dalam:
- Riset pasar dan analisis kompetitor
- Pemantauan harga dan produk
- Analisis sentimen dan opini publik
- Prediksi tren dan perilaku konsumen
2. Efisiensi dan Otomatisasi
Tanpa web scraping, pengumpulan data dari web harus dilakukan secara manual, yang sangat memakan waktu dan rentan terhadap kesalahan. Web scraping mengotomatisasi proses ini, menghemat waktu dan sumber daya.
3. Akses terhadap “Hidden Web”
Banyak informasi di internet tidak terindeks oleh mesin pencari atau tidak tersedia melalui API. Web scraping memberikan akses ke data yang mungkin sulit ditemukan atau dikumpulkan.
4. Agregasi Data dari Berbagai Sumber
Web scraping memungkinkan pengumpulan dan konsolidasi data dari berbagai situs web, memberikan pandangan komprehensif tentang topik tertentu.
5. Pemantauan Perubahan Real-time
Dengan menjadwalkan script web scraping, Anda dapat memantau perubahan pada situs web secara real-time dan mendapatkan notifikasi tentang informasi baru atau perubahan penting.
Etika dan Legalitas Web Scraping
Web scraping berada di area abu-abu secara hukum. Berikut beberapa hal penting yang perlu dipertimbangkan:
Aspek Hukum dan Etika:
Terms of Service (ToS): Selalu periksa ToS situs web yang ingin di-scrape. Banyak situs web secara eksplisit melarang scraping.
Robots.txt: File ini memberikan petunjuk tentang area situs yang boleh dan tidak boleh di-crawl. Mengabaikannya bisa dianggap melanggar etika.
Rate Limiting: Jangan mengirim terlalu banyak permintaan dalam waktu singkat. Ini bisa membebani server dan dianggap sebagai serangan DoS.
Data Pribadi: Berhati-hatilah saat mengumpulkan informasi pribadi, yang mungkin melanggar undang-undang perlindungan data seperti GDPR.
Hak Cipta: Data yang di-scrape mungkin dilindungi oleh hak cipta. Pastikan penggunaan data sesuai dengan prinsip penggunaan wajar.
Best Practices dalam Web Scraping
Identifikasi Diri: Sertakan informasi kontak dalam user-agent atau berikan notifikasi ke administrator situs.
Caching: Simpan data yang sudah di-scrape untuk mengurangi beban pada server situs.
Waktu Jeda: Tambahkan jeda waktu antara permintaan untuk mengurangi beban.
Gunakan API jika tersedia: Jika situs menyediakan API, gunakan itu sebagai alternatif scraping.
Pelajari Struktur Situs: Pahami struktur situs sebelum memulai scraping untuk proses yang lebih efisien dan tepat sasaran.
Kesimpulan
Web scraping adalah alat yang sangat berguna dalam arsenal pengumpulan data. Dengan memahami teknik, alat, dan pertimbangan etis yang terlibat, Anda dapat memanfaatkan kekuatan web scraping untuk mendapatkan wawasan berharga dari web. Namun, selalu ingat untuk menggunakannya secara bertanggung jawab dan dengan mempertimbangkan hak-hak pemilik situs web dan pengguna.
Saat dilakukan dengan benar, web scraping dapat membuka pintu ke lautan data yang tidak terstruktur di web dan menyediakannya dalam format yang dapat digunakan untuk berbagai aplikasi data-driven.